

Free AI Inference APIs with Generous Limits
After Paperclip AI ate my ClaudeCode 5-hour session tokens in 30 minutes and couldn’t handle a basic onboarding (creating agents) task, I decided to try another strategy.
I configured my AI team manually to use OpenCode and Hermes Agent with free AI inference providers. I am still yet to discover how Paperclip AI will perform in general, but along the way, I discovered and collected a set of reliable AI API providers.
If you are a bootstrapped founder or AI enthusiast of any kind, your compute budget for R&D can be exactly zero dollars.
Here is the blueprint. These are the actual, production-ready free tiers you can use today. No 14-day trials. No credit card walls. Just raw inference.
1. Google AI Studio
Google’s free-tier gives you Gemini Flash 3.5, Gemma 4 31B, and more. Permanently.
The real-world caveat? It’s rate-limited per minute on the free tier, but you can always integrate it into your processes with a bit control.
Don’t use it for rapid-fire, real-time chat loops. Use it for asynchronous tasks that you can queue.
Gemini 3.5 Flash is fairly good for planning and orchestration. You can delegate the simpler tasks to Gemma 4, which you get 1500 requests per day on free-tier.
2. NVIDIA NIM
Nvidia NIM (build.nvidia.com) gives you free developer access to over 100 models. Minimax-M3 and nemotron-3-ultra-550b-a55b are pretty capable mid-range reasoning models.
Nvidia’s API is 100% OpenAI-compatible. You change the base_url to Nvidia’s endpoint, drop in your nvapi- key, and your existing code just works.
NVIDIA NIM Free-Tier Limits
A flat rate of 40 requests per minute.
That is more than enough for local prototyping. Use it to power your terminal assistants. Plug it into IDE tools like OpenCode or Cline. Use it to validate multi-turn tool calling before you push to production.
But there is a catch: They may use your prompts to train their models. Avoid using Nvidia with sensitive/propriety data.
Also, It’s an evaluation sandbox. There is no production SLA. They want to sell you enterprise licenses to self-host on your own GPUs later.
Let them. For now, take the free compute and build your agent logic without watching a billing dashboard.
3. OpenRouter
OpenRouter has been one of my goto providers. It doesn’t provide great uptime for every model, but it offers pretty much every LLM on their platform, including pretty powerful free models during preview periods.
It’s an aggregator. You use one API key and get access to everything.
They host dozens of free open-source models with generous limits.
Each model/inference-privoder has different free-tier limits. Currently nvidia/nemotron-3-ultra-550b-a55b:free , google/gemma-4-31b-it:free, and openai/gpt-oss-120b:free are my go-to models for basic tasks.
4. Cerebras
When latency matters and you don’t need large models, Cerebras shines.
Cerebras’s speed is mind-blowing.
I got 1304 T/s (0.52 seconds) when I tried Gemma 4 on Cerebras.
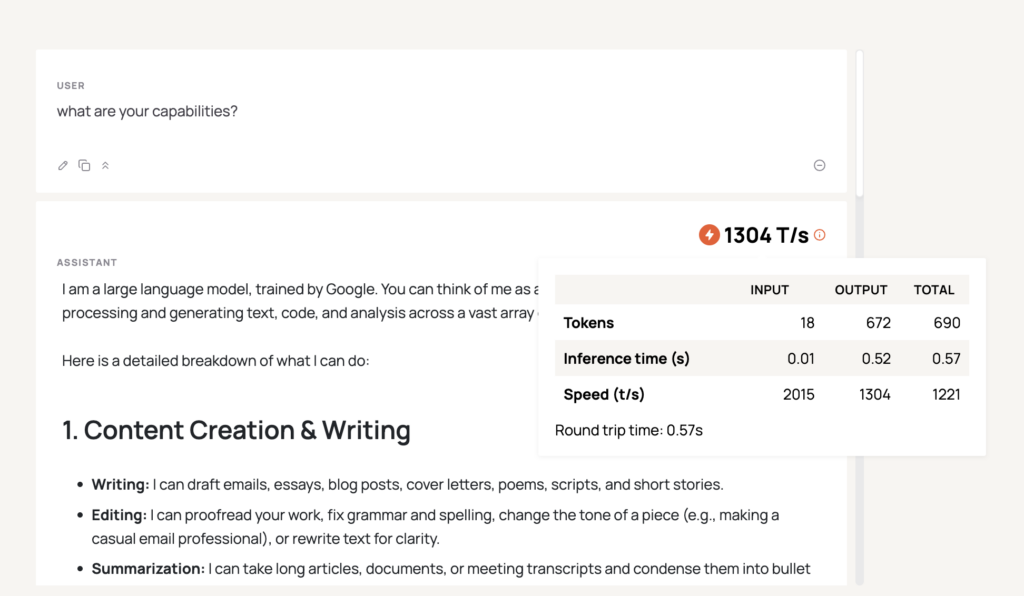
Gemma 4 is a game-change for price and speed for tasks such as content writing and quick prototyping.
Cerebras’ free-tier daily limits
Their free tier gives you a million tokens a day with a 30req/min rate limit.

5. Groq
Second to Cerebras, Groq provides lightening-fast inferences too. It runs open-source models like Llama 3 on custom LPU hardware. Sufficient for basic tasks. They hit 500 to 700 tokens per second. The free tier hands you about 1,000 requests daily.
6. OpenCode Zen
Although it’s free-tier is not as generous as others and it’s mostly for coding, I must add it to the list.
Its free models give about 200 requests per 5–12 hour window. Their best free model is currently Big Pickle. On the lower spectrum, they provide DeepSeek V4 Flash and Nemotron 3 Super , which you can use for basic tasks.
Conclusion
You can get about ~5.000 requests / day for free. It’s best you configure your agents to use models fit for their tasks. Use the heavyweight models for planning and orchestration. Use mid-range and small models for creative writing, simple coding, etc.
It’s plenty for casual users. For heavy users like myself, It’s just an experiment for my Paperclip AI instance. I still pay for Claude, Google, and OpenCode Go subscriptions. I still hit my limits (using manually). I used to have ChatGPT/Codex and Cursor subscriptions too, and I was till hitting my limits. So, don’t cancel your subscriptions yet, but consider implementing these free models into your n8n workflows, Github Actions, etc.
Closing tip: Create separate Google/Gmail accounts for your projects, sign up to each platform, and get ~5.000 req/day for each of your projects.